Most developers use LLMs like ChatGPT or Claude straight out of the box and wonder why the code looks nothing like what they’d write in production.
Here’s the thing: LLMs are trained on the average of the internet. For iOS engineers, this is particularly painful. There’s significantly less Swift code in the training data compared to JavaScript or Python. What you get is code that compiles, but doesn’t follow the patterns you use in production: no dependency injection, missing your testing approach, ignoring your architecture conventions.
The gap between tutorial code and production/commercial code is massive.
A Three-Year Journey
When ChatGPT first came out, I was excited. As someone that made a career through optimizing developer efficency through tools and automations it resonated immediately. So I started trying to understand how to leverage it and at first the results were terrible. The code worked in the most basic sense, but it violated every principle I’d established over a decade of Swift development.
I needed a better way.
At first, I had very elaborate prompts that would try to inline the coding style I wanted into every message. To avoid copy-pasting constantly, I used shortcuts: I could just type _swift and it would inject this massive prompt into my editor of choice. As rules grew I just put them and files and my shortcuts would just force LLM to load those files for me. That helped, but it was cumbersome still.
Then MCP protocol came out last year, so naturally I built a custom MCP (Model Context Protocol) server that used LLM self-reflection to decide which rules to load based on the user’s request. This was necessary for me because every tool had different configuration formats: Cursor had its approach, Claude had another, and I wanted a single source of truth for how my code is written as I explore all the different available coding tools. The MCP server would analyze the request, determine the context, and load the appropriate rules dynamically.
But that’s now changed: Over the last 7 months, LLMs have improved dramatically. What required complex orchestration before now works with a simpler approach. I no longer rely on the MCP server for rule loading. In-fact I almost dropped all MCP’s and use CLI when I need something. Instead, I use a straightforward rule-index.md file that tells the LLM which rules to load for which tasks.
Progressive disclosure means I don’t need to load all the rules every time, instead I can rely on my LLM to pick what it needs.
Agents + Rules
The solution is conceptually simple: give your LLM two things.
- AGENTS.md: A high-level guide to your repository (architecture, commands, workflow expectations), everyone does that now.
- Rule files: Specific patterns for different domains (dependency injection, testing, view architecture, commits)
Think of AGENTS.md as the README for your LLM, and rule files as your team’s coding standards broken into digestible, contextual pieces that are loaded on demand, rather than using polluting your context window when they are not neccesary.
The AGENTS.md Template
Your AGENTS.md file serves as the entry point. I usually use consistent architecture for the majority of my iOS projects. I even have a template in my course that I basically leverage whenever I have to create a new project or adjust a client’s project to fit my approach.
Here’s the structure I use:
# Agent Guide
## Purpose
Agents act as senior Swift collaborators. Keep responses concise,
clarify uncertainty before coding, and align suggestions with the rules linked below.
## Rule Index
- @ai-rules/rule-loading.md — always load this file to understand which other files you need to load
## Repository Overview
- Deep product and architecture context: @ai-docs/
[Fill in by LLM assistant]
## Commands
[Fill in by LLM assistant]
- `swiftformat . --config .swiftformat`: Apply formatting (run before committing)
- `swiftlint --config .swiftlint.yml`: Lint Swift sources and address custom rules
- `pre-commit run --all-files`: Verify hooks prior to pushing
## Code Style
- Swift files use 4-space indentation, ≤180-character width, and always-trailing commas
- Inject dependencies (Point-Free Dependencies) instead of singletons; make impossible states unrepresentable
## Architecture & Patterns
[Fill in by LLM assistant]
- Shared UI lives in `SharedViews`; shared models and utilities in `Shared*` modules
- Use dependency injection for all services and environment values to keep code testable
## Key Integration Points
**Database**: [Fill in by LLM assistant]
**Services**: [Fill in by LLM assistant]
**Testing**: Swift Testing with `withDependencies` for deterministic test doubles
**UI**: [Fill in by LLM assistant]
## Workflow
- Ask for clarification when requirements are ambiguous; surface 2–3 options when trade-offs matter
- Update documentation and related rules when introducing new patterns or services
- Use commits in `<type>(<scope>): summary` format; squash fixups locally before sharing
## Testing
[Fill in by LLM assistant]
## Environment
[Fill in by LLM assistant]
- Requires SwiftUI, Combine, GRDB, and Point-Free Composable Architecture libraries
- Validate formatting and linting (swiftformat/swiftlint) before final review
## Special Notes
- Do not mutate files outside the workspace root without explicit approval
- Avoid destructive git operations unless the user requests them directly
- When unsure or need to make a significant decision ASK the user for guidance
- Commit only things you modified yourself, someone else might be modyfing other files.Notice the [Fill in by LLM assistant] markers. Agents like Codex will populate these sections on first load by analyzing your codebase. If your model of choice doesn’t just nudge them to do so.
You get a living document that adapts to your project.
Rule Files: Domain-Specific Guidance
I’ve experimented with countless formats for rule files. XML-like tags work best for top-level rule definitions. Markdown handles the detailed explanations inside.
Is this optimal? Maybe, maybe not. But it’s worked reliably for over 2 years across dozens of projects, so I’m not fixing what isn’t broken (as any good engineer says 😉).
Each rule file covers a specific domain. Here’s the anatomy using my general.md as an example:
Structure Elements
1. Primary Directive
<primary_directive>
You are an ELITE Swift engineer. Your code exhibits MASTERY through SIMPLICITY.
ALWAYS clarify ambiguities BEFORE coding. NEVER assume requirements.
</primary_directive>Sets the tone and non-negotiables.
2. Cognitive Anchors
<cognitive_anchors>
TRIGGERS: Swift, SwiftUI, iOS, Production Code, Architecture, SOLID,
Protocol-Oriented, Dependency Injection, Testing, Error Handling
SIGNAL: When triggered → Apply ALL rules below systematically
</cognitive_anchors>Helps the LLM recognize when to apply these rules.
3. Core Rules with Priorities
<rule_1 priority="HIGHEST">
**CLARIFY FIRST**: Present 2-3 architectural options with clear trade-offs
- MUST identify ambiguities
- MUST show concrete examples
- MUST reveal user priorities through specific questions
</rule_1>Explicit priorities guide the LLM’s decision-making.
4. Implementation Patterns
<pattern name="dependency_injection">
// ALWAYS inject, NEVER hardcode
protocol TimeProvider { var now: Date { get } }
struct Service {
init(time: TimeProvider = SystemTime()) { }
}
</pattern>Show, don’t just tell. Code examples cement the pattern.
5. Checklists and Anti-Patterns
<checklist>
☐ NO force unwrapping (!, try!)
☐ ALL errors have recovery paths
☐ DEPENDENCIES injected via init
☐ PUBLIC APIs documented
☐ EDGE CASES handled (nil, empty, invalid)
</checklist>
<avoid>
❌ God objects (500+ line ViewModels)
❌ Stringly-typed APIs
❌ Force unwrapping optionals
</avoid>Concrete dos and don’ts.
The Smart Index: rule-loading.md
This file tells the LLM which rules to load based on context. Here’s a snippet:
# Rule Loading Guide
## Rule Loading Triggers
### 📝 general.md - Core Engineering Principles
**Load when:**
- Always
- Starting any new Swift project or feature
- Making architectural decisions
**Keywords:** architecture, design, performance, quality, best practices
### 🧪 testing.md - Swift Testing Framework
**Load when:**
- Writing any tests
- Setting up test suites
- Testing async code
**Keywords:** test, @Test, @Suite, testing, unit test, integration test
### 🎨 view.md - SwiftUI Views
**Load when:**
- Creating new SwiftUI views
- Building UI components
- Implementing view performance optimizations
**Keywords:** SwiftUI, View, UI, interface, componentThe file also includes two critical sections:
Quick Reference
// When working on a new feature:
// Load: general.md, mcp-tools-usage.md, view.md, view-model.md, dependencies.md
// When writing tests:
// Load: general.md, mcp-tools-usage.md, testing.md, dependencies.md
// When reviewing code:
// Load: general.md, mcp-tools-usage.md, commits.mdPrebuilt scenarios for common workflows.
Loading Strategy
1. **Always load `general.md` and `mcp-tools-usage.md` first** - foundation
2. **Load domain-specific rules** based on the task
3. **Load supporting rules** as needed (e.g., testing when implementing)
4. **Keep loaded rules minimal** - Only what's directly relevant
5. **Refresh rules** when switching contexts or tasksEnsures the LLM loads the right rules at the right time without polluting context.
The LLM reads this once at the start, then loads relevant rules on demand. No more dumping your entire ruleset into every conversation.
Here’s what it looks like when the LLM loads rules on demand:
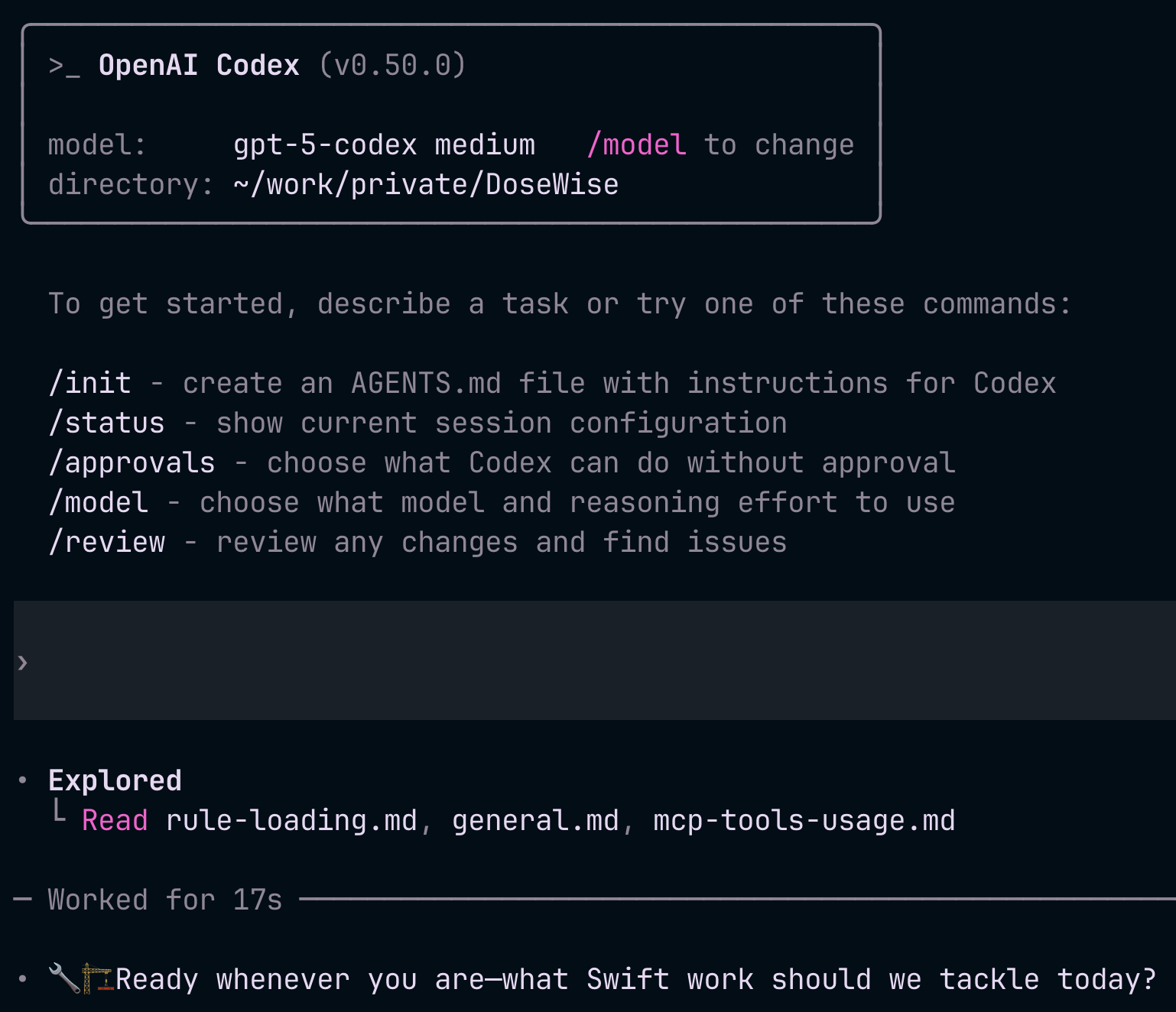
The LLM automatically identifies which rules to load based on your request context - no manual selection needed.
What This Gives You
Let’s be concrete about the benefits:
- Code that matches YOUR style: The LLM writes dependency injection the way you write it, not how some tutorial does it
- Consistent patterns across conversations: Whether you’re in Claude, ChatGPT, or Cursor, the rules travel with you
- Less refactoring: The first pass is closer to production-ready
- Better onboarding: New team members see your standards encoded explicitly, kind of like SwiftLint but more about architecture, and patterns.
In my experience, setting up this system saves hours of refactoring and code review back-and-forth.
My Rule Set: 12 Files Covering Every Domain
I maintain 12 rule files covering:
- Core engineering principles
- Dependency injection patterns
- SwiftUI view architecture
- ViewModel coordination
- Swift Testing conventions
- Commit message standards
- MCP tool usage
- Development workflow
- Self-improvement patterns
- …and more
Each file is 130-560 lines of focused, actionable guidance with code examples and explicit priorities.
These rules evolved over last 3 years of daily LLM use on production Swift applications. They encode patterns I’ve ended up prefering after 15+ years of Cocoa engineering, adapted for the era of AI-assisted development.
If you want the complete Swift-specific rule set, it’s available as part of my course at swiftystack.com.
Getting Started
Here’s how to implement this in your project today:
- Create
AGENTS.mdin your repository root using the template above - Create
ai-rules/folder for your rule files - Start with
rule-loading.md: Define which rules load when - Add
general.md: Your core engineering principles - Expand domain-specific rules as you encounter patterns worth encoding
Start small. Don’t try to encode everything at once. Add rules when you notice the LLM making the same mistake twice.
The Bottom Line
LLMs have improved dramatically since ChatGPT 3.5. But out-of-the-box, they still give you the average of the internet not the professional best practices you’d write manually. For iOS engineers writing Swift, that average is particularly far from production quality.
A small investment in AGENTS.md and rule files gives you massive improvement in code quality. The LLM writes code that looks like you wrote it, because you taught it your patterns explicitly.
Stop complaining about LLM’s not producing good code if you didn’t tell them what good code is FOR YOU. Teach your agents to write like you.